JPA?
정의
- Java Persistence API ::= Java ORM(Object-Relational Mapping)을 위한 명세
- SQL과 유사한, 객체를 이용한 JPQL(Java Persistence Query Language) 지원
- 객체 상속 관계 사용 가능
- 객체 참조 관계 유지 가능
객체지향 설계와 RDB의 설계를 둘 다 해치지 않으면서 둘 사이의 매핑을 지원 ─ 즉, 필요한 SQL을 자동으로 구성
JPA 사용
Hibernate와 같은 JPA 구현체(JPA Provider)를 이용하거나, 직접 구현하여 이용하면 된다
Spring Data JPA
JPA에 대한 추상화된 모듈을 제공하여 보다 쉬운 사용을 가능하게 한다
JPA 사용 정리
예시 코드
| 설명 | 링크 |
|---|---|
| 전체 프로젝트 | jpa-example |
| 예시 코드 - 기본 CRUD | |
| 예시 코드 - Converter | |
| 예시 코드 - Embed | |
| 예시 코드 - @OneToOne 단방향 | |
| 예시 코드 - @OneToOne 양방향 | |
| 예시 코드 - @ManyToOne 단방향 | |
| 예시 코드 - @ManyToOne, @OneToMany 양방향 | |
| 예시 코드 - @OneToMany 단방향 | |
| 예시 코드 - @ElementCollection | |
| 예시 코드 - @JoinTable | |
| 예시 코드 - InheritanceType.SINGLE_TABLE | |
| 예시 코드 - InheritanceType.JOINED | |
| 예시 코드 - InheritanceType.TABLE_PER_CLASS |
EntityManager
Persistence context; 영속 컨텍스트
- DB에서 읽어오거나 DB로 삽입하고자 추가한 객체들은 영속 객체(Persistence object)들로, EntityManager가 관리하는 영속 컨텍스트에 보관된다
- 트랜잭션 커밋 시점 또는 명시적인 flush() 호출로 영속 컨텍스트의 변경 사항이 DB에 실제 반영된다
- 영속 객체는 (타입 + 식별자)를 키로 하는 Map으로 관리된다
- 이를 이용해 조회(find)하려는 엔티티가 이미 컨텍스트에 있다면 DB에 쿼리를 보내지 않고 즉시 컨텍스트의 객체를 반환한다
- @Id를 @GeneratedValue(strategy = GenerationType.IDENTITY)로 구성하는 경우, 커밋 전에 식별자를 얻기 위해 미리 insert 쿼리가 실행된다
- 영속 객체 생애 주기
- Managed : 변경이 존재하면 DB에 반영됨
- Detached : EntityManager가 닫혔거나, 롤백되어 분리된 상태. 변경이 DB에 반영되지 않음
- Removed : 커밋 또는 flush() 호출 시 DB에서 삭제
트랜잭션(@Transactional 포함) 안에서 엔티티 수정 시 트랜잭션 커밋 시점에 자동 반영. 또는 flush()로 즉시 반영
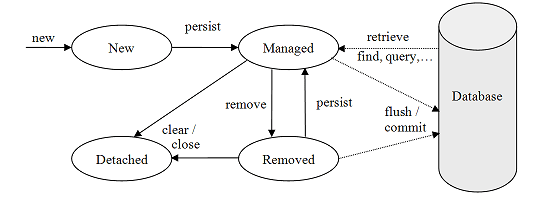
<이미지 - Entity Life Cycle>
EntityManager를 직접 관리하는 경우
- EntityMaganerFactory를 만든다
- EntityManager가 필요할 때마다 팩터리로부터 하나 생성하고, 사용한 뒤에 직접 닫는다
- 트랜잭션이 여러 메서드에 걸쳐있는 경우, 동일한 EntityManager를 이용함을 직접 보장해야 한다
메서드 파라미터로 넘기거나 ThreadLocal을 이용하거나... 구현은 자유
EntityManager를 컨테이너에서 관리하는 경우
@PersistenceContext로 현재 EntityManager 인스턴스를 주입받으면 된다. Spring Data JPA 에서는 @Autowired도 가능
메서드
- void persist(Object entity)
- <T> T find(class<T> entityClass, ...)
- <T> T getReference(class<T> entityClass, Object primaryKey)
- 쿼리 지연 실행. 우선 T 프록시를 반환. 프록시 최초 사용 시 쿼리 실행되며, DB에 없으면 EntityNotFoundException
- 사용하는 EntityManager를 닫기 전에 프록시를 사용해야 쿼리가 실행된다
- Hibernate의 경우, final entity class에 대하여 쿼리 즉시 실행
- void remove(Object entity)
- void detach(Object entity)
- void clear()
- <T> T merge(T entity)
- boolean contains(Object entity)
- void flush()
- void refresh(Object entity, ...)
- void lock(Object entity, LockModeType lockMode, ...)
객체를 영속 컨텍스트에 등록하여 변경이 DB에 반영되도록 한다
지정 (타입 + 기본키)를 이용해 객체를 조회한다. 영속 컨텍스트에 있다면 DB를 조회하지 않고 해당 객체를 반환한다. DB에도 없으면 null 리턴
객체를 DB에서 삭제하도록 한다
객체를 영속 컨텍스트로부터 분리한다. 따라서 영속 객체의 변경 사항이 DB에 반영되지 않도록 한다
영속 컨텍스트를 비우고 모든 객체를 detached 상태로 변경한다
객체를 현재 영속 컨텍스트에 등록한다
객체가 영속 컨텍스트에 포함됐는지 여부
영속 컨텍스트를 DB로 동기화한다
특정 객체를 DB로부터 동기화한다
영속 컨텍스트의 객체를 잠근다
@Entity
- DB 입출력 단위
- 기본 생성자 필수. @Id 최소 한 개 지정 필수
- 원활한 프록시 동작을 위해 protected 이상, non-final 클래스로 정의
↓ @Entity 예
@Table
- @Entity 클래스에 name, catalog, index, schema, UniqueConstraint 설정 추가
- name 속성만 필요하다면 @Entity에 직접 설정 가능
@Id
기본키 컬럼 명시. 기본 타입 + Wrapper 타입, Date, BigInteger, BigDecimal 타입만(should) 가능
@GeneratedValue, @SequenceGenerator, @TableGenerator
- strategy = GenerationType.IDENTITY
- generator = "gen_name" : 시퀀스 또는 ID 생성 테이블 이용
↓ 기본키 자동 설정
DB 설정(MySQL auto_increment, PostgreSQL serial) 그대로 이용. insert 실행 후 실제 값이 설정된다
↓ 1. 시퀀스
↓ 2. 테이블
@Temporal
date, time, timestamp 컬럼 명시. 각각 java.sql.Date, java.sql.Time, java.sql.Timestamp에 매핑
@Column
- 필드 또는 getter 메서드에 대해 컬럼 명시
- name : 컬럼 이름
- unique : 이 컬럼만으로 unique key인 경우
- length : 텍스트 길이
- precision, scale : decimal 정밀도
- insertable : insert 포함 여부
- updatable : update 포함 여부
↓ java
@Transient 또는 transient 한정자
해당 필드는 persistence 대상에서 제외
@Enumerated
enum 매핑 : EnumType.ORDINAL, STRING 2가지만 가능
@Convert, @Converter
커스텀 컨버터 지정
@DynamicInsert, @DynamicUpdate
- Non-null 컬럼만 insert, update 시 이용
- 세션 당 최초 1번만 적용된다
- 쿼리 실행 후 생략된 컬럼 값이 변경되더라도, 객체에 설정되지 않는다
다른 엔티티/값 포함
Value Class
- 여타 언어들의 ValueType에 해당하는 클래스
- 값을 변경하는 연산은 새 인스턴스를 반환한다
- JPA에서는 @Embeddable 클래스로 Value Class를 정의한다
값을 이용해 다른 인스턴스와 비교하며, 자기 자신을 변경하지 않는다
유의사항
- 엔티티 포함이 많아질수록 코드 결합도가 증가한다
- 모든 테이블이 엔티티인 것은 아니다 서로 다른 두 엔티티의 라이프사이클은 독립적이다
- 포함하려는 대상과의 관계가 엔티티:엔티티인지, 엔티티:밸류인지 명확히 파악해야 한다
- @OneToMany 매핑을 사용하려는 경우, 정말로 모든 연관 엔티티가 필요한 지 고려할 것
- @ManyToMany 매핑을 사용하려는 경우, JoinTable을 엔티티로 사용하는 게 낫지 않은 지 고려
엔티티:밸류 관계를 엔티티:엔티티 관계로 사용하면 불필요한 추가 작업이 발생할 수 있다
Hibernate 컬렉션 자료형
| 사용 타입 | Hibernate가 실제로 인스턴스화하는 타입 |
|---|---|
| List | ArrayList |
| Set | HashSet |
| Map | HashMap |
| SortedSet | TreeSet |
| SortedMap | TreeMap |
Sorted 자료형의 정렬자 지정
- 요소가 Comparable하면 @org.hibernate.annotations.SortNatural 사용
- 그렇지 않으면 @org.hibernate.annotations.SortComparator로 Comparator 지정
@org.hibernate.annotations.OrderBy
JPA의 것과 다르게 JPQL order by 절을 이용해 DBMS가 정렬하도록 한다
↓ java
@Embedded로 @Embeddable 타입 포함
- 엔티티 필드 일부를 하나의 @Embeddable 클래스로 묶을 수 있다.
- @AttributeOverride를 이용해 동일 @Embeddable 클래스를 여러 개 이용하는 경우에 대처할 수 있다
- @Embeddable 클래스의 필드 일부도 다른 @Embeddable 클래스로 묶을 수 있다
@Embeddable 클래스로 복합키 정의
복합키 클래스는 Serializable 인터페이스를 구현하고, equals(), hashCode()를 적절히 재정의해야 한다.
@SecondaryTable 포함
- 포함하는 대상은 secondary table, 포함하는 쪽은 primary table
- Default로 primary table의 기본키를 그대로 이용하여 조회한다
- pkJoinColumns으로 secondary table 기본키를 설정할 수 있다
- Select에 이용되는 쿼리는 left outer join이다
엔티티 사이의 1:1, 1:N, N:1, M:N 매핑
@OneToOne
- 1→1 단방향 매핑
- @JoinColumn으로 기본키를 설정한다. @SecondaryTable과는 다르게 조인 컬럼 자체를 영속 필드로 가질 수는 없고, 대신 매핑된 엔티티 변경에 따라 자동으로 조인 컬럼 값을 변경한다
- 두 테이블의 기본키가 동일한 경우 @JoinColumn 대신 @PrimaryKeyJoinColumn을 이용할 수 있다
- 1→1 단방향 매핑을 그대로 양방향 매핑으로 이용
이 경우 신규 엔티티 삽입을 위해 식별자가 필요하므로, 참조하는 테이블의 신규 엔티티가 먼저 영속 컨텍스트에 등록되어야 한다
↓ java
@ManyToOne, @OneToMany
- N→1 단방향 매핑
- N→1 단방향 매핑을 그대로 양방향 매핑으로 이용
- 1→N 단방향 매핑
@OneToOne 단방향 매핑과 다를 게 없다. 다만 N:1 관계이므로 두 테이블의 기본키가 동일할 수는 없다
↓ java
@JoinTable
- JoinTable? : 검색에 필요한 두 테이블의 키 컬럼만 모은 테이블
- 1→N 단방향 매핑 예
- @OneToMany 대신 @ManyToMany 이용 가능
- mappedBy를 이용해 양방향 매핑 가능
fetch 속성 - 쿼리 지연 실행
Default로 처음부터 연관 테이블을 함께 조회(left outer join)한다. fetch 속성으로 변경할 수 있다
↓ java
cascade 속성 - 영속성 전이 규칙
- 기본값은 {}으로 아무런 추가 작업이 없다
- CascadeType.PERSIST : EntityManager::persist 시 연관 엔티티도 추가
- CascadeType.REMOVE : EntityManager::remove 시 연관 엔티티도 삭제
- CascadeType.DETACH : EntityManager::detach 시 연관 엔티티도 분리
- CascadeType.REFRESH : EntityManager::refresh 시 연관 엔티티도 갱신
- CascadeType.MERGE : EntityManager::merge 시 연관 엔티티도 추가
- CascadeType.ALL
@ElementCollection으로 프로젝션
- Embeddable 클래스도 가져올 수 있다
- 당연히 JPQL로도 가능하다
클래스 상속과 테이블 매핑
InheritanceType.SINGLE_TABLE
클래스 계층 구조가 하나의 테이블을 공유하고, 각각 일부분씩 매핑. 구분을 위한 컬럼(@DiscriminatorColumn) 존재
InheritanceType.JOINED
각 클래스는 키를 공유하는 별개의 테이블에 대응
InheritanceType.TABLE_PER_CLASS
각 클래스는 별개 테이블에 대응 → 키 관리에 유의
@MappedSuperclass - 공유 컬럼 정의
add_date, upd_date 같은 일반적인 공유 컬럼을 한 곳에 정의할 수 있다
트랜잭션
RESOURCE_LOCAL 타입 트랜잭션
- JPA의 EntityTransaction을 이용한 트랜잭션 처리
- Spring Data JPA는 공유 EntityManager 인스턴스로 직접 트랜잭션 관리하는 것을 허용하지 않는다
↓ java
JTA(Java Transaction API) 타입 트랜잭션
- 직접 트랜잭션을 관리하는 경우
- 외부 컨테이너에서 관리하는 경우 : @Transactional 이용
- @Transactional은 전후에 트랜잭션의 시작, 커밋을 자동으로 진행한다
- 클래스, 메서드 둘 다에 적용 가능하고, 메서드에 붙으면 클래스의 것을 오버라이드한다
- @Transactional 메서드가 다른 @Transactional 메서드를 호출하고, 해당 메서드에서 롤백이 발생하면 default로 전역 롤백한다
↓ java
RuntimeException을 포함하여, 예외를 감지하면 자동으로 롤백한다
↓ java
잠금
선점 잠금; Pessimistic lock; select for update
트랜잭션 내에서, 차후 수정을 위해 미리 행을 잠근다
↓ java
비선점 잠금; Optimistic lock
테이블에 버전 컬럼(정수, timestamp)이 존재하여, 순차적인 update만 허용하도록 강제
↓ java
하이버네이트 관련 추가 기록
- 지연 로딩된 프록시 인스턴스의 실제 클래스 반환
- 쿼리 생성 설정
- 로깅 관련 설정
- @Subselect
↓ java
DBMS 버전에 맞춰 설정 필요
↓ ini
↓ application.properties
쿼리 결과를 엔티티로 사용할 수 있게 해준다
↓ java
JPA Query
JPQL; JPA Query Language
- SQL과 유사한 쿼리 언어로, 테이블-컬럼 대신 엔티티-속성 이름을 이용한다
- 엔티티 이름 ::= @Entity 적용한 클래스 이름. name 속성을 이용한 경우 해당 값
- 일반적인 SQL 문도 사용할 수 있다
- JPQL은 항상 실행되며, 결과 엔티티가 이미 컨텍스트에 존재하면 버려진다
- update, delete는 기존 영속 컨텍스트에 반영 안 됨
↓ sql
↓ java
↓ java
↓ java
select 절
- select 절은 반환할 매핑에 대한 완전한 정보를 가져야 한다. 따라서 "select *"은 유효한 문법이 아니다
↓ sql
from 절(조인)
- where 절에서 엔티티의 필드가 다른 엔티티를 참조하는 경우, 자동으로 join된다
- join 명시
- join fetch
- Entity의 field가 다른 엔티티의 참조/컬렉션일 때, join은 해당 필드를 프록시/컬렉션 래퍼로 설정한다. 아래와 같이 join fetch로 실행하면 field까지 모두 가져와 설정한다
- distinct 사용없이 "select e1 from Entity1 e1 join fetch e1.field e2"를 실행한 리스트의 e1과 e2의 개수는 같음에 유의
- distinct 사용없이 "select e1 from Entity1 e1 join fetch e1.field e2"를 페이징 실행하면 중복을 제거함에 유의
↓ sql
↓ sql
데이터가 많은 경우 큰 오버헤드 발생
where 절
↓ sql
↓ java
group by 절
집계함수 없이 사용 == distinct
↓ sql
집계함수
| 함수 | 반환 타입 |
|---|---|
| count | Long |
| max, min | 대상 타입 |
| avg | Double |
| sum | Long, Double, BigInteger, BigDecimal |
집계함수 사용 without group by
↓ sql
집계함수 사용 with having
↓ sql
order by 절
- select 절에 정의한 매핑에 포함되거나, 그로부터 직접 도달할 수 있는 필드만 이용 가능하다
- 또, 정렬 가능하기 위해 필드의 타입은 Comparable해야 한다
↓ sql
페이징
↓ java
서브쿼리
where, having 절에서 사용 가능
↓ sql
조건식
- case when condition then expr1 else expr2 end
- case target when expr1 then expr2 else expr3 end
- coalesce(expr1, expr2[, ...])
- nullif(expr1, expr2)
최초로 null이 아닌 것 반환. SQL의 IFNULL 대신 사용 가능
두 값이 같으면 null. 다르면 expr1
리터럴
| 타입 | 표기 |
|---|---|
| 문자열 | 'string', 'It''s good' |
| 수 | 123, 123L, 123D, 123F |
| 시각 | DATE {d '2000-01-01'} TIME {t '12:34:56'} TIMESTAMP {ts '2000-01-01 12:34:56.789'} |
| Boolean | true, false |
| Enum | package.EnumName.FIELD_NAME |
함수
문자열
- concat(str1, str2[, ...])
- substring(str, start[, length])
- trim([METHOD] [CHAR] from] str)
- METHOD : LEADING, TRAILING, BOTH(default)
- CHAR : default ' '
- lower(str), upper(str)
- length(str)
- locate(search, str[, start])
start부터 search 문자열을 찾아 최초 위치(1부터 시작)를 반환한다. 없으면 0
수
- abs(math_expression)
- sqrt(math_expression)
- mod(math_expression1, math_expression2)
시각
- CURRENT_DATE
- CURRENT_TIME
- CURRENT_TIMESTAMP ↓ Hibernate
- YEAR(), MONTH(), DAY(), HOUR(), MINUTE(), SECOND()
컬렉션
- size(collection)
- index(collection_alias)
특정 인덱스의 요소만 가져올 때 사용한다
↓ sql
타입
- type(x) : x의 타입
- treat(x as Entity) : x를 Entity로 캐스팅
Criteria
- 문자열 대신 Java API로 쿼리 동적 생성
- Single selection
- Multi selection
- Join
- Where
- Group by
- Order by
- Literal
- Type
- Expressions
↓ java
↓ java
↓ java
↓ java
↓ java
↓ java
↓ java
↓ java
↓ java
↓ java
@StaticMetamodel
엔티티 필드에 대한 메타데이터를 제공하여 Criteria 이용시 정적인 타입 체크를 강화해준다
↓ 엔티티
↓ 메타 모델
↓ Criteria 사용
메타 모델 자동 생성
"jpa model generator" 검색하면 여러 외부 라이브러리 또는 IDE 애드온이 검색되니 참고
Spring Data JPA 사용
JpaRepository<Entity, ID>
- 이 인터페이스를 상속하면 findAll, findById, save, delete, flush 등의 메서드를 자동으로 구성한다
- 명명규칙에 맞는 새 메서드들을 자동으로 구현한다
JpaRepository -> PagingAndSortingRepository -> CrudRepository
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is, Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull, Null | findByAge(Is)Null | … where x.age is null |
| IsNotNull, NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection<Age> ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection<Age> ages) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
JPQL
↓ java
페이징
- Pageable
- findFirst, findTop, findFirstN, findTopN 명명규칙 이용
↓ java
↓ java
Specification을 이용한 검색 조건 조합
- Specification을 인자로 받는 검색 메서드 정의
- Specification 정의
- Specification static 메서드를 이용한 새 조건 생성
- not(Specification<T>)
- where(Specification<T>)
- and(Specification<T>)
- or(Specification<T>)
↓ java
↓ java
- © Donggi Kim. MIT License
- w3css : No license
- highlight.js : BSD-3-Clause License
- MathJax : Apache License 2.0
- qrcodejs : MIT License